
凌 星
星河如練夜無邊,凌渡星芒夢似煙

用 AI 搭建一个自己的个人博客
用 AI 搭建一个自己的个人博客 写这篇内容主要是想看一遍最近正在做的事情:把 Obsidian、Codex、opencode 里产生的内容,慢慢整理成一个可以长期沉淀的个人博客。 我之前一直把信息放在 Obsidian 里,比如网站资料、AI 总结、日常记录、各种资料链接。这样做适合自己查阅,但不太适合公开展示,也不方便把一些已经整理好的内容分享出去。所以最近开始用 AI 辅助搭一个个人博客,把每天自动化总结保存下来的内容,挑一部分整理成文章。 为什么选 Hexo现在用的是 Hexo 框架,没有后端。对新手来说,Hexo 的好处是结构清楚、部署简单、资料多,而且文章就是 Markdown 文件。只要能把主题、配置和文章目录跑通,后面维护成本并不高。 当然,Hexo 相关项目很多,不同主题的结构也不完全一样。对小白来说,直接打开项目可能会懵:哪些是配置,哪些是主题,哪些是生成文件,哪些地方可以改,哪些地方不应该动。 所以我的思路是先让 AI 读一遍项目结构,再让它把 Hexo 官方文档、主题结构、已有文章和我的需求整合起来,输出一份能看懂的说明。这样后面我再继续改站点,就不是盲改...
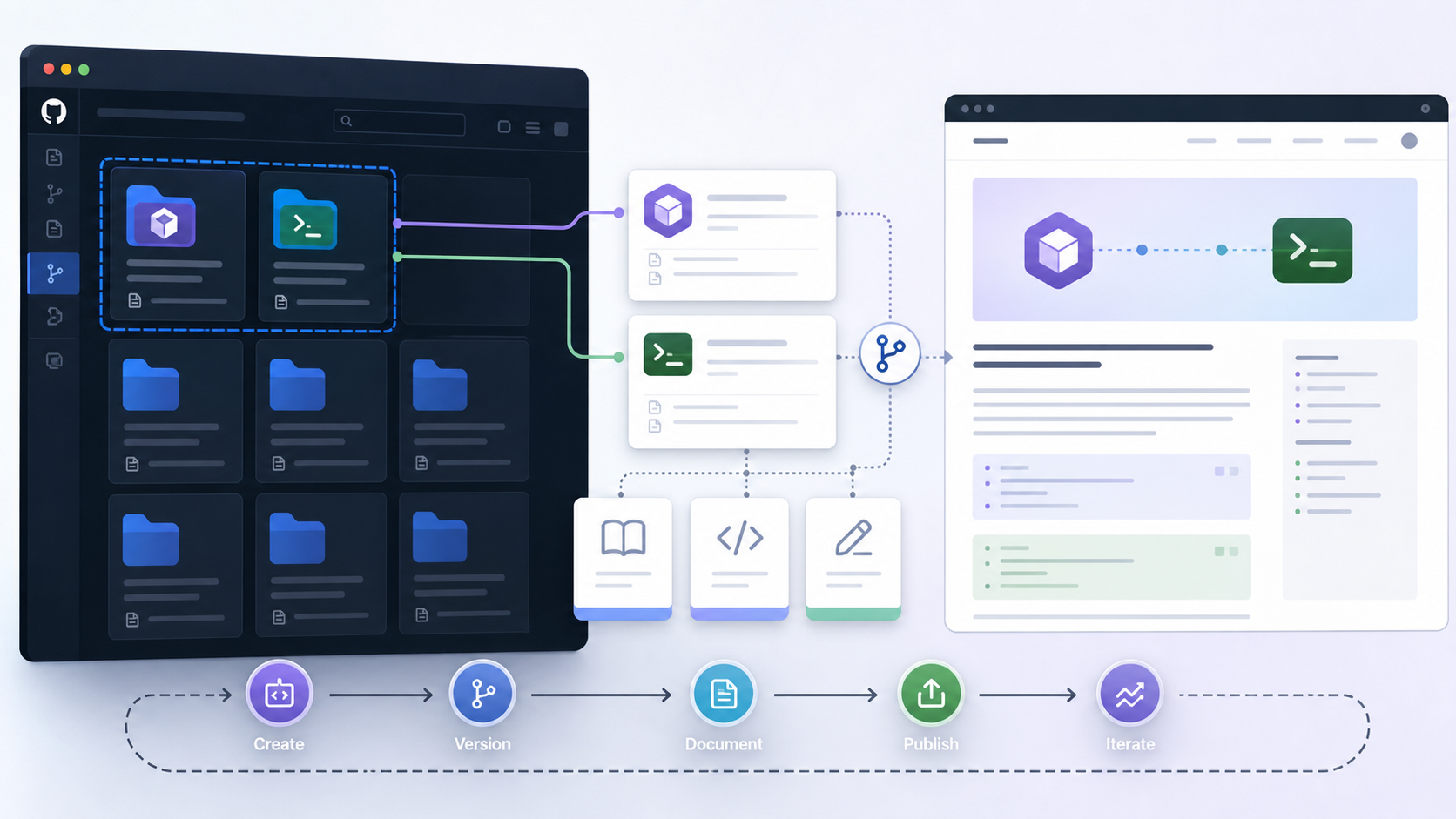
把两个 Codex Skill 变成可维护的个人工具库
把一个 skill 上传到 GitHub,表面上是在发布一段脚本或一份 SKILL.md,实际上是在把个人工作流产品化。只要它能被安装、被阅读、被复现、被别人提出问题,它就不再只是本机上的一段提示词,而是一件可以长期维护的工具。 这次准备放上 GitHub 的两个 skill,分别对应 AI 编程交接链路里的两个动作:opencode-share 负责从共享链接里提取干净 transcript,opencode-handoff 负责把共享链接可靠地送到另一个人或另一台机器。一个偏解析,一个偏传输;一个把上下文变清楚,一个让上下文到达正确位置。 为什么要拆成两个解析 share 页面和设计 handoff 协议是两类问题:前者关注输入格式、页面数据、输出结构;后者关注身份、权限、收件箱、验证和失败处理。拆开之后,每个仓库的边界更清楚,也更容易让别人只安装自己需要的部分。 Skill 不是普通说明文档普通 README 是写给人看的,skill 还要写给 agent 看。它需要说明触发场景、输入边界、工具调用方式、失败时怎么处理、什么动作不能做。尤其是涉及跨会话、跨机器、第三方 t...

OpenCode Handoff:用 GitHub 做会话交接收件箱
一次 OpenCode 会话结束后,最常见的需求不是”永久保存聊天记录”,而是”让另一个人、另一台机器、或者下一个会话接着做”。传统做法是 /share 之后把链接发到聊天软件里,再靠对方手动打开、复制、总结、导入。链路能跑,但上下文散、身份弱、审计困难,也很容易丢。 opencode-handoff 的思路很直接:用 GitHub 私有仓库当邮局,把 OpenCode share URL 作为一封待处理的信。发送方 agent 负责验证、签名、推送;接收方 agent 在新会话里检查收件箱,拉取、验证、抓取 transcript,然后把它作为第三方数据注入当前上下文。 为什么选择 GitHubGitHub 已经提供认证、私有访问控制、提交历史、协作者权限和可选 GPG 签名验证。对于个人多机器和小团队来说,复用这些能力比重新搭一个消息服务更实际。shared 模式适合小组共用收件箱,P2P 模式适合个人之间点对点交接。 五层验证真正决定这个 skill 质量的,是接收侧验证。进入收件箱的 handoff 应该逐层检查:文件名格式、发件人白名单、内容字节级合规、GitHub A...

OpenCode Share:把共享会话整理成可复用知识
OpenCode 的分享链接很适合把一次 AI 编程会话发给别人,但原始页面里往往混着运行时状态、工具调用、token 统计、模型元数据和内部引用。对人来说,真正有用的不是这些噪声,而是用户提出了什么问题、助手给了什么答复、对话顺序如何、会话里有哪些可以继续追踪的上下文。 opencode-share 这个 skill 解决的就是这件事:从 OpenCode share URL 或保存下来的 HTML 里提取有意义的 transcript,把它整理成干净的 Markdown,并在需要时输出 JSON。它更像一个”会话清洗器”,把一次临时对话变成可以归档、复盘、交接的知识材料。 为什么要做成 skill如果只是写一个脚本,使用者需要记住命令、参数和输出位置。做成 Codex skill 之后,入口就变成自然语言:把链接丢给 Codex,让它分析这段 OpenCode 共享会话并总结有效内容。skill 负责告诉 Codex 应该抓哪些信息、忽略哪些噪声、以什么结构交付结果。 它保留什么它不把 OpenCode 页面当作完整网页备份,而是当作”对话知识源”来解析。应该保留的是用户可...